# MySQL 连接池 c3p0、dbcp、druid、hikari
作者:小傅哥
博客:https://bugstack.cn (opens new window)
沉淀、分享、成长,让自己和他人都能有所收获!😄
本文的宗旨在于通过简单干净实践的方式,向读者展示 SpringBoot 应用程序对接 MySQL 时,在使用不同连接池以及不使用连接池时,在增删改查的一个性能对比。这也包括更新和查询时,索引字段的关键性。
内容开始之前,你知道1张21个字段的表,存放100万数据,大于会占用多少空间容量吗?如果这100万数据在不使用连接池的方式,10个并发一条条插入,要多少时间?
问题1需要350M左右、问题2需要2-3小时。可能你会说,这字段不一定都多长,这插入不知道的机器配置。但其实这些并不是重要的,如果你做过一次你肯定能说出自己一个所在机器配置下的数据验证结果。而本文则借着对 MySQL 连接池的 ApacheBench 压测验证,让读者伙伴可以学习到相关的知识。
本文涉及的工程:
- xfg-dev-tech-connection-pool:https://gitcode.net/KnowledgePlanet/road-map/xfg-dev-tech-connection-pool (opens new window) - 工程内含有环境的安装脚本;
mysql-docker-compose.yml、apachebench-docker-compose.yml、road_map_8.0.sql
# 一、案例背景
拿100万订单数据,压到数据库中!
本章节小傅哥会带着大家初始化一个空的数据库表,并向数据库表中写入100万数据。之后在分别不使用连接池和使用不同的连接池(c3p0、dbcp、druid、hikari)写入数据,测试各个连接池的性能。这也能让大家知道,日常我们应该选择哪个连接池。
# 二、环境配置
因为本章节很偏实操,所以需要大家做下提前安装好 Docker 环境,以便于执行本章节工程中的脚本和代码。可参考Java简明教程系列内容 Docker、Portainer 学习安装和使用。
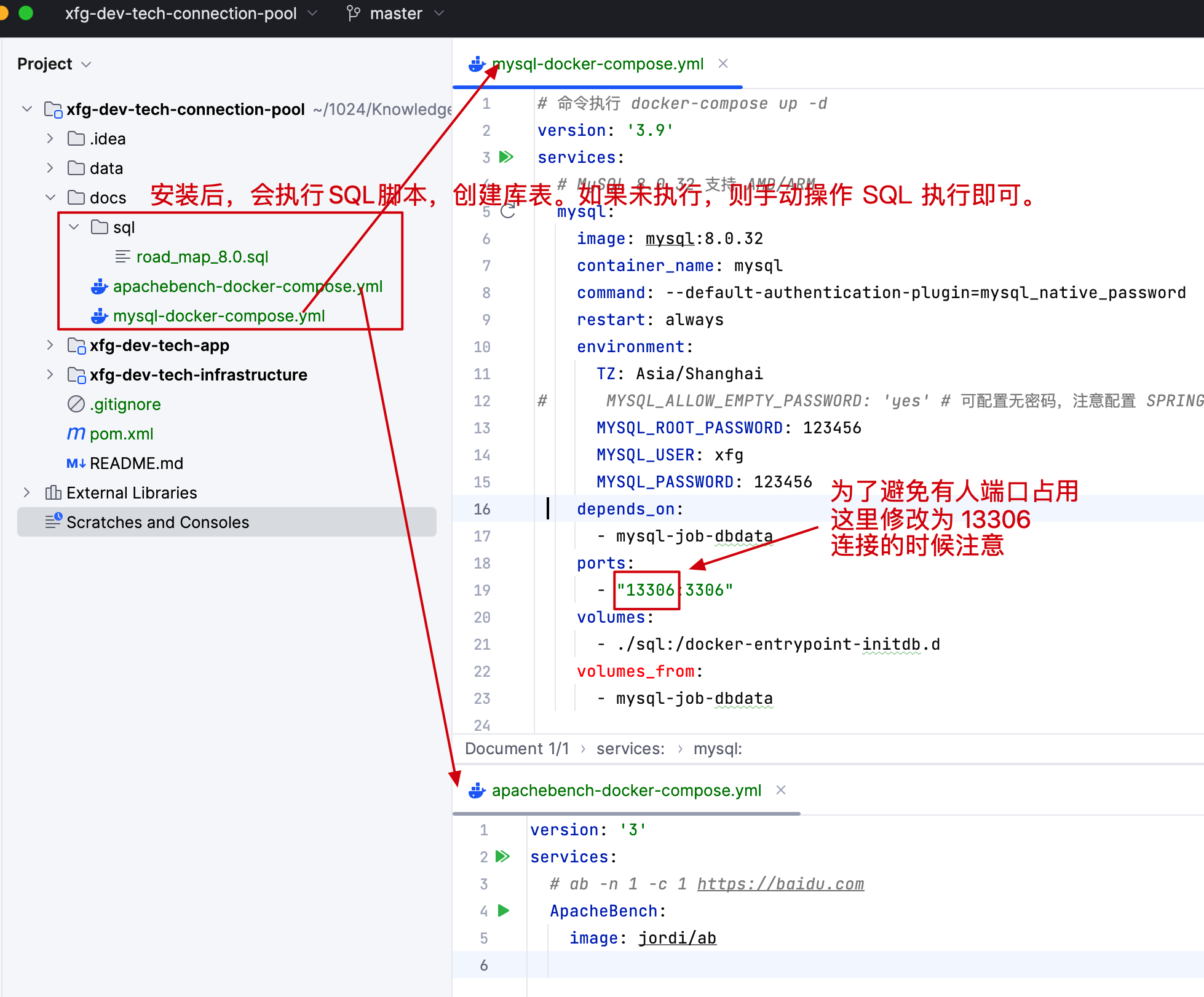
- 在 IntelliJ IDEA 打开 xfg-dev-tech-connection-pool 分别点开 mysql-docker-compose、apachebench-docker-compose,之后点击安装即可。
- 执行完脚本,你可以得到一份安装好的 MySQL 8.0 并安装了数据库表。另外一份是用于压测使用的 ApacheBench (opens new window)
- 连接 MySQL 的工具,推荐使用开源免费的 Sequel Ace (opens new window)
# 三、工程说明
在 xfg-dev-tech-connection-pool 工程中提供了不同连接池的配置和一些非常常用的 SQL 操作,以及提供了对应的接口进行压测使用;
| 序号 | 接口 | 说明 |
|---|---|---|
| 1 | http://127.0.0.1:8091/api/mysql/cacheData | 用于缓存数据的接口,拿缓存好的数据压测更新、查询 |
| 2 | http://127.0.0.1:8091/api/mysql/insert | 插入数据接口 |
| 3 | http://127.0.0.1:8091/api/mysql/updateOrderStatusByUserId | 使用索引字段 userId 更新订单状态 |
| 4 | http://127.0.0.1:8091/api/mysql/updateOrderStatusByUserMobile | 使用无索引字段 userMobile 更新订单状态 |
| 5 | http://127.0.0.1:8091/api/mysql/updateOrderStatusByOrderId | 使用索引字段 orderId 更新订单状态 |
| 6 | http://127.0.0.1:8091/api/mysql/selectByUserId | 使用索引字段 userId 查询订单 |
| 7 | http://127.0.0.1:8091/api/mysql/selectByUserMobile | 使用无索引字段 userMobile 查询订单,测试中添加索引 |
| 8 | http://127.0.0.1:8091/api/mysql/selectByOrderId | 使用有索引字段 orderId 查询订单 |
| 9 | http://127.0.0.1:8091/api/mysql/selectByOrderIdAndUserId | 区分度高的索引字段在前,区分度低的索引字段在后 |
| 10 | http://127.0.0.1:8091/api/mysql/selectByUserIdAndOrderId | 区分度低的索引字段在前,区分度高的索引字段在后 |
- 具体代码实现可以直接对照工程来看,以及按需添加SQL语句进行性能压测验证。
# 四、库表语句
SQL:xfg-dev-tech-connection-pool/docs/sql/road_map_8.0.sql
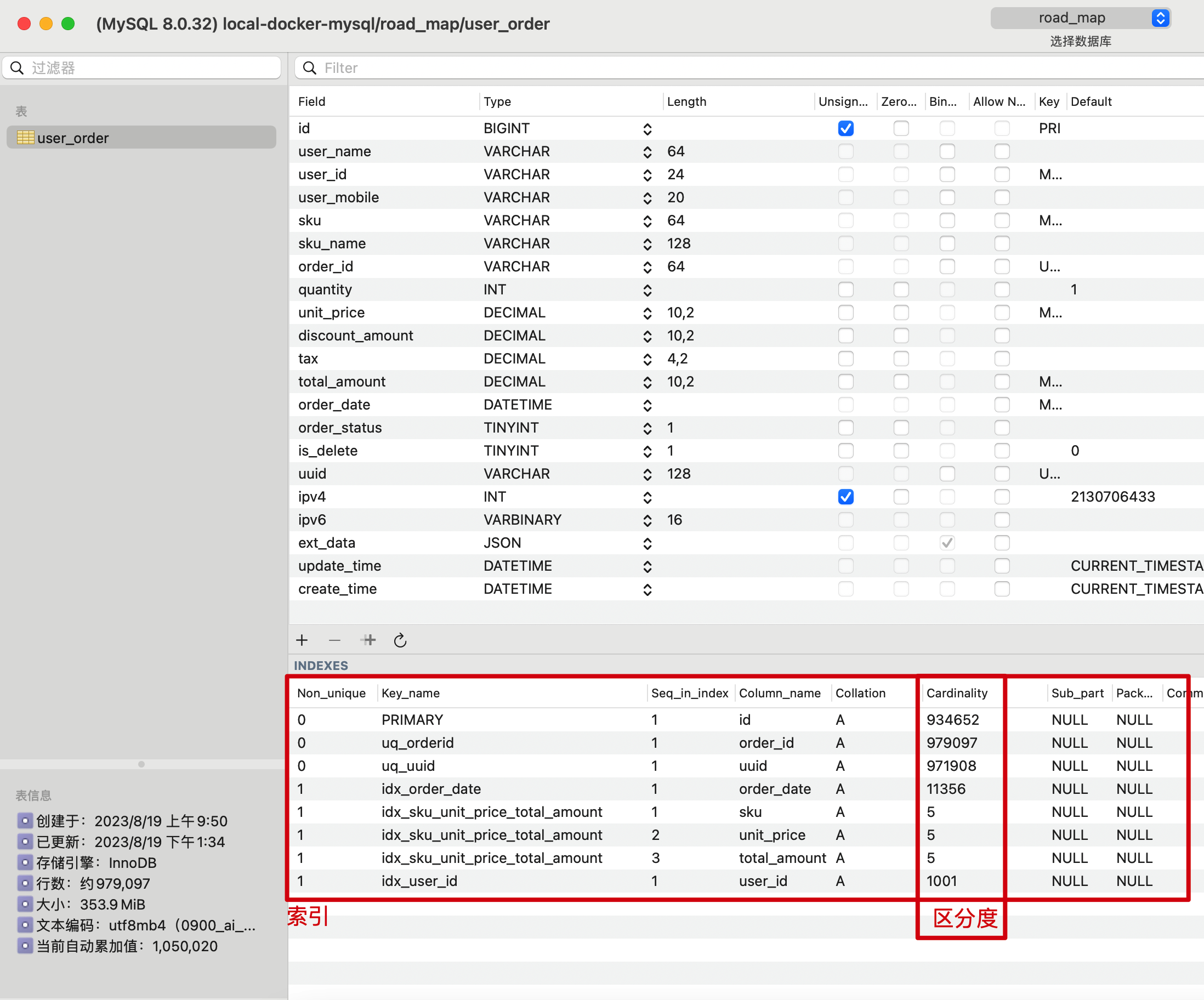
- 这是本节所需要测试的一个订单表和测试前所建的索引字段。以及初始化了100万数据,占用350M空间。
- 接下来,我们就可以做测试验证了。
# 五、压测指令
ApacheBench 官网教程:https://httpd.apache.org/docs/2.4/programs/ab.html (opens new window)

常用的如:ab -c 20 -n 1000 http://127.0.0.1:8091/hi - 20个并发1000次
# 六、压测验证
首先在测试前,正式测试前,你大概需要花费几十分钟来初始化100万数据。执行脚本;ab -c 20 -n 1000000 http://127.0.0.1:8091/api/mysql/insert - 如果你在工程中配置了 no-pool 大概要花费几个小时才能跑完,这就使用和不使用连接池的差距。
# 1. 连接池比对
条件;
- 插入1万条数据
- 连接池配置 initialPoolSize=5、minPoolSize=5、maxPoolSize=20
- 此时数据库已经有100万数据,分别用几个链接方式插入数据。hikari 放到最后,它是 SpringBoot 的默认连接池。
- 脚本;
ab -c 20 -n 10000 http://127.0.0.1:8091/api/mysql/insert
| no-pool | c3p0 | dbcp | druid | hikari | |
|---|---|---|---|---|---|
| 耗时 | 88.990 seconds | 24.228 seconds | 33.656 seconds | 25.971 seconds | 25.002 seconds |
| 50% | 155ms | 39ms | 60ms | 45ms | 43ms |
| 80% | 223ms | 61ms | 86ms | 64ms | 64ms |
| 90% | 291ms | 75ms | 103ms | 75ms | 76ms |
- 通过对比可以发现,如果不使用连接池,会比使用连接池,要占用更多的时间连接数据库使用数据库。
- c3p0、hikari 的性能还是非常不错的,dbcp 相对是弱一些的。所以这可以给你在使用连接池时有一个参考。也可以结合你的机器再次进行压测验证。
# 2. 更新对比
条件;
- 使用接口,向内存加入600条数据。每个测试方式,分别消耗200条。
ab -c 10 -n 600 http://127.0.0.1:8091/api/mysql/cacheData - 之后使用无索引字段、有索引但区分度不高的字段以及使用有索引区分度非常好的字段来更新。
- 脚本;
ab -c 20 -n 200 http://127.0.0.1:8091/api/mysql/updateOrderStatusByUserMobileab -c 20 -n 200 http://127.0.0.1:8091/api/mysql/updateOrderStatusByUserIdab -c 20 -n 200 http://127.0.0.1:8091/api/mysql/updateOrderStatusByOrderId
| 无索引 | 有索引-区分度不高 | 有索引-区分度很高 | |
|---|---|---|---|
| 耗时 | 24小时+ | 24小时+ | 0.432 seconds |
| 50% | 24小时+ | 24小时+ | 35ms |
| 80% | 24小时+ | 24小时+ | 48ms |
| 90% | 24小时+ | 24小时+ | 67ms |
- 无索引的时候;会把整个表的这个记录,全部锁上。那么越执行越慢,最后拖垮数据库。甚至可能1天都执行不完。
- 有索引-区分度不高;几乎是一样的,如果你批量的对一个用户的所有数据都更新,也会锁很多记录。
- 有索引-区分度很高;只要你锁的是自己的一条记录,就与别人没有影响。效率也会非常高。
# 3. 查询对比
条件;
- 查询100万加的数据库表记录,每次缓存记录5000条数据id;
ab -c 10 -n 5000 http://127.0.0.1:8091/api/mysql/cacheData - userId 有索引、orderId 有索引、userMobie 无索引。
- 每次查询的时候,都要关闭服务重启,避免有缓存干扰结果。
- 脚本:
ab -c 20 -n 5000 http://127.0.0.1:8091/api/mysql/selectByUserMobileab -c 20 -n 5000 http://127.0.0.1:8091/api/mysql/selectByUserIdab -c 20 -n 5000 http://127.0.0.1:8091/api/mysql/selectByOrderIdab -c 20 -n 5000 http://127.0.0.1:8091/api/mysql/selectByOrderIdAndUserIdab -c 20 -n 5000 http://127.0.0.1:8091/api/mysql/selectByUserIdAndOrderId
| 无索引 | 有索引-区分度不高 | 有索引区分度高 | 高在前 | 低在前 | |
|---|---|---|---|---|---|
| 耗时 | 6小时+ | 8.343 seconds | 2.051 seconds | 2.168 seconds | 3.279 seconds |
| 50% | 7s | 13ms | 7ms | 7ms | 11ms |
| 80% | 9s | 20ms | 10ms | 11ms | 17ms |
| 90% | 15s | 26ms | 13ms | 13ms | 22ms |
- 无索引,还是查询字段的。非常危险。
- 不要在一些区分度不高的字段建索引。当然本案例中,userId 最多也就1000来个用户所产生的1百万数据,这样的情况更适合分库分表。
- 区分度很高的字段,查询效率会非常好。
- 把高区分度的索引字段放在前面,更有利于查询。—— 注意不要测试完上一个,直接测试下一个。有缓存的情况下,会影响对比结果。
这就是整个数据库表的压测过程了。如果你有使用的诉求,需要做技术调研,那么一定要做一些这样的压测处理。这样有真实数据才好讲道理。另外需要面试的伙伴,你不是总没有数据吗,来吧,按照这个压一压!

京公网安备 11030102010881号
| GPL Licensed | Copyright © 2019 小傅哥,All rights reserved.