# Ai MCP + ELK 系统日志,排错提效 100%!
作者:小傅哥
博客:https://bugstack.cn (opens new window)
沉淀、分享、成长,让自己和他人都能有所收获!😄
大家好,我是技术UP主小傅哥。
自从 Ai MCP 模型上下文协议,2024年11月,推出开放标准以后。2025年,就进入了全面的 MCP 服务落地。也正因如此,程序员👨🏻💻的学习就又多了一项新的应用技能,同时也成了面试热门问题。如:“你的项目,有使用 AI 方面的能力进行提效吗?” 解封下码农的双手🙌🏻!

我能哪些方面使用 Ai 提效呢?
在互联网程,序员工程开发方面,关于 Ai 提效最为常见的,也是市面上使用最多的,就是各类的 Ai 编码软件。如 cursor、trae.ai、IntelliJ IDEA 中的各类 Ai 插件,都可以辅助我们完成项目的编码操作。甚至一些简单的 HTML 页面,几乎在刚开始开发阶段,可以快速搭建起来,确实非常提效。
不过这些都是固定的软件,他们并没有深度结合到业务场景中,从整个研发的生命周期看,还有非常多的节点可以被 Ai 提效。如;需求评审、研发设计、系统发布、代码评审、单测用例、业务监控、问题排查&故障分析等。都可以深入自身的业务,运用 Ai 开发进行提效。
这里尤其是问题排查和故障分析,在互联网企业中,尤其是大厂的业务,几乎每天都要配和运营的反馈的客诉,系统的报警日志,性能的降低反馈,进行人工检索系统监控、日志、分析,这部分要投入大量的人工成本,虽然可能系统并不是真的有问题,但也要一遍遍的排查这些问题。
所以,结合这样的场景,小傅哥在带着大家的实战项目,也逐步的引出关于 Ai 在应用项目上的提效处理。今天分享的一个场景就是基于 Ai MCP 分析系统的 ELK 日志。后面还会分析关于监控、数据库一起分析。
🧧 文末提供了小傅哥技术社群全套的17个应用实战项目,一次加入可以获得全部的文档、源码、视频,嘎嘎提高能力!
# 一、系统说明
小傅哥带着社群伙伴,做了一套 《拼团交易平台系统》,因为拼团是非常重要的 toc 业务场景,也是拼多多、腾讯、京东等服务平台,交易支付时候,最为常见的一种营销手段。它可以通过用户自传播方式增强交易量,也是拼多多最开始起家形成巨大规模的一个业务逻辑。
该系统采用了 DDD 领域驱动设计进行建模,拆分领域模块边界,形成;活动领域、人群领域、交易领域,来构建拼团营销交易流程,达到试算、锁单、结算等步骤流程。这个过程中提炼了通用设计模式,规则树、责任链,可以非常有效的统一的治理流程编排实现。
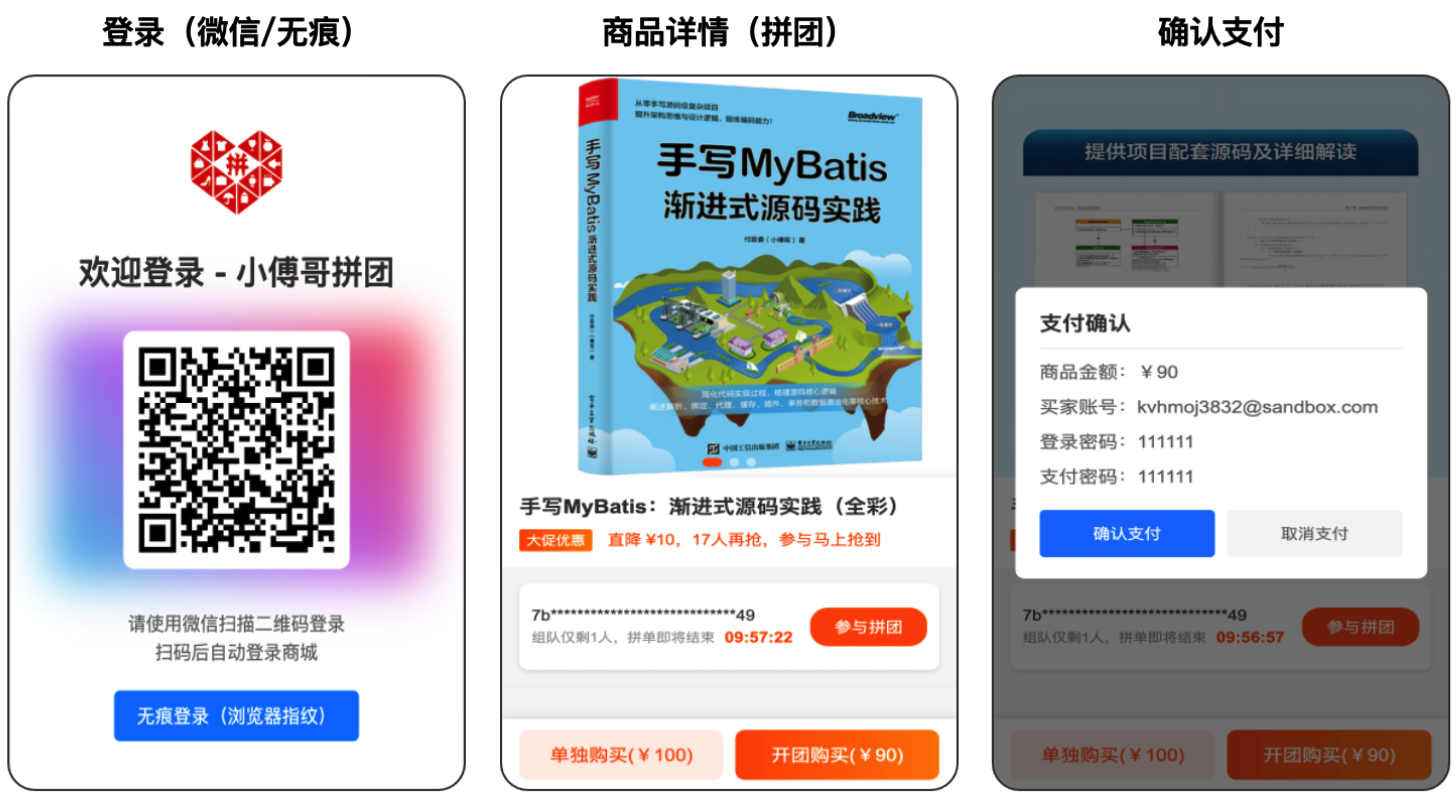
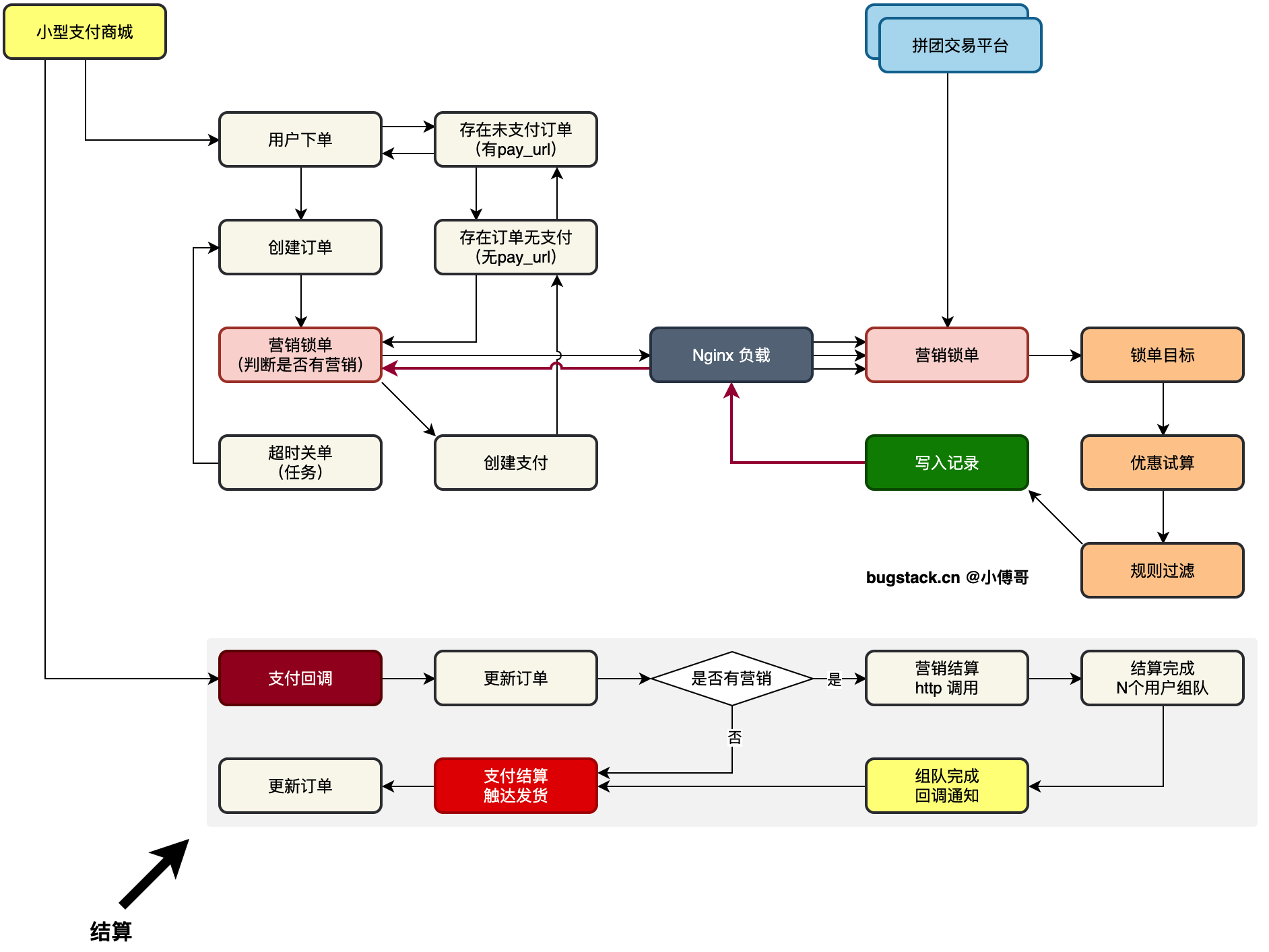
如图,是两套微服务的对接链路。
- 首先,在小型支付商城,创建订单的过程中,调用拼团营销锁单。这个时候就拿到了当笔订单的优惠金额。之后创建支付订单唤起收银台,之后用户就可以按照最终的优惠金额进行支付了。
- 之后,在支付完成后,收到回调消息,进行营销拼团进度结算。直至拼团组队进度完成,在回调给支付商城,触达交易结算。
这样一整套完整的交易营销流程,是非常真实的实际场景对接处理方案。尤其是营销场景下的复杂的试算、规则的过滤,再到结算的处理,都是使用了非常巧妙的编码操作,使用了非常好的设计模式进行设计。这块非常有的学!
# 二、配置日志
# 1. 系统部署(ELK)
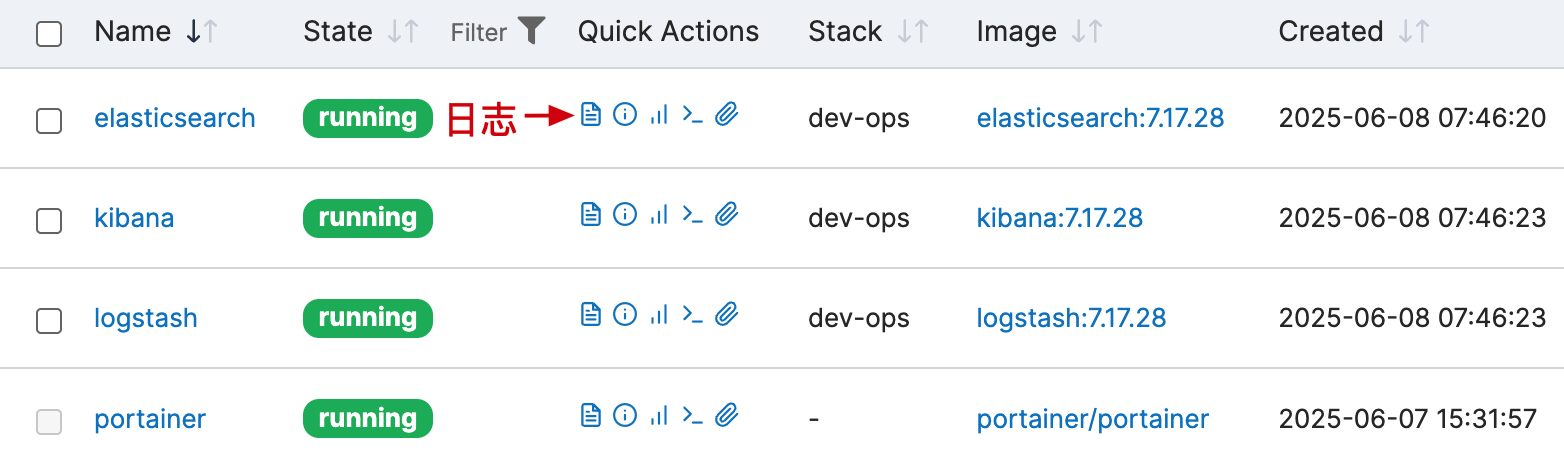
- 基于 Docker 部署 ELK 系统,采集上报日志。
# 2. 上报配置
<!-- 上报日志;ELK -->
<springProperty name="LOG_STASH_HOST" scope="context" source="logstash.host" defaultValue="127.0.0.1"/>
<!--输出到logstash的appender-->
<appender name="LOGSTASH" class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<!--可以访问的logstash日志收集端口-->
<destination>${LOG_STASH_HOST}:4560</destination>
<encoder charset="UTF-8" class="net.logstash.logback.encoder.LogstashEncoder"/>
</appender>
<root level="info">
<appender-ref ref="CONSOLE"/>
<!-- 异步日志-INFO -->
<appender-ref ref="ASYNC_FILE_INFO"/>
<!-- 异步日志-ERROR -->
<appender-ref ref="ASYNC_FILE_ERROR"/>
<!-- 上报日志-ELK -->
<appender-ref ref="LOGSTASH"/>
</root>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
- 通过增加 LogstashTcpSocketAppender 上报系统日志到 ELK。
# 3. 生产日志
开始下面的操作之前,需要启动 SpringBoot 服务,访问接口,让系统产生一些运行日志。
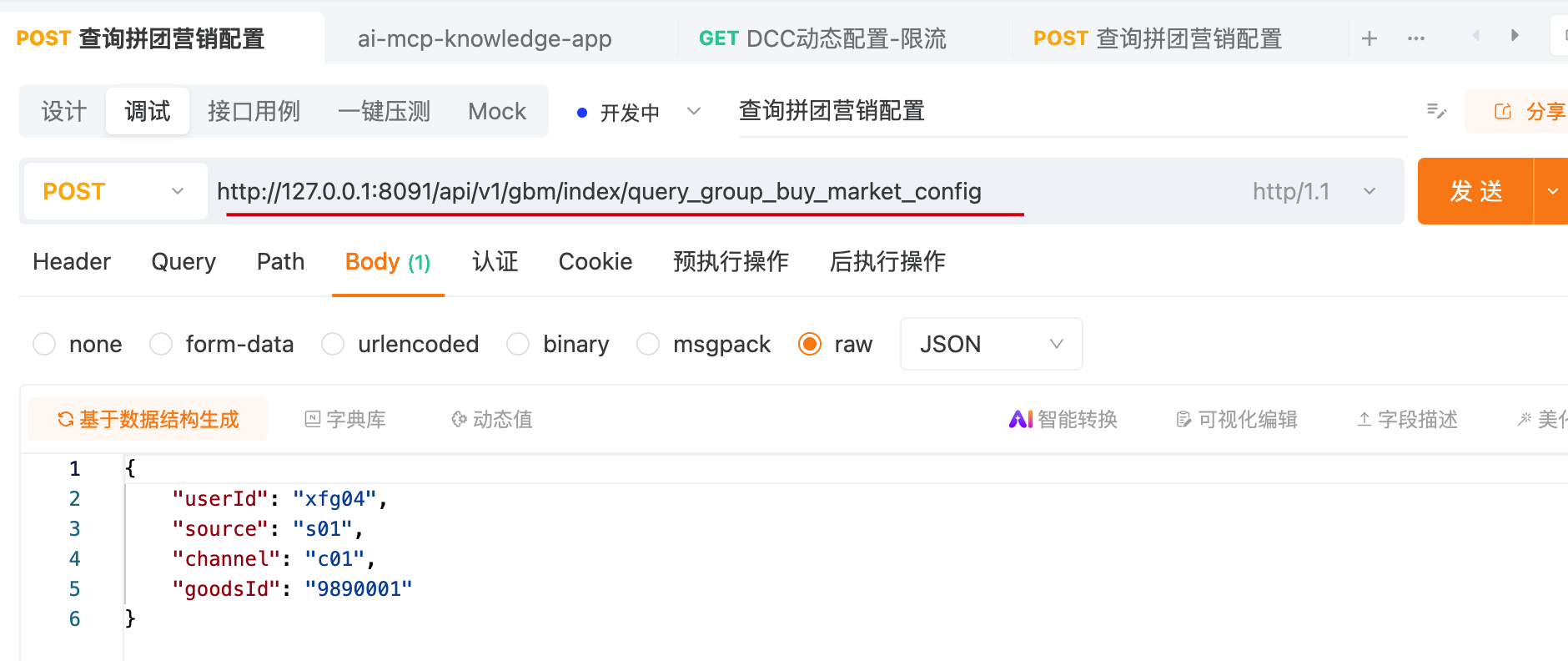
25-06-08.08:05:08.441 [http-nio-8091-exec-2] INFO ZJCalculateService -b601d8d5-ff62-4adb-8260-16d8b6af53ef 优惠策略折扣计算:0
25-06-08.08:05:08.445 [http-nio-8091-exec-2] INFO EndNode -b601d8d5-ff62-4adb-8260-16d8b6af53ef 拼团商品查询试算服务-EndNode userId:xfg04 requestParameter:{"channel":"c01","goodsId":"9890001","source":"s01","userId":"xfg04"}
25-06-08.08:05:08.451 [http-nio-8091-exec-2] INFO MarketIndexController -b601d8d5-ff62-4adb-8260-16d8b6af53ef 查询拼团营销配置完成:xfg04 goodsId:9890001 response:{"code":"0000","data":{"activityId":100123,"goods":{"deductionPrice":20.00,"goodsId":"9890001","originalPrice":100.00,"payPrice":80.00},"teamList":[],"teamStatistic":{"allTeamCompleteCount":0,"allTeamCount":2,"allTeamUserCount":4}},"info":"成功"}
2
3
- 访问的是拼团试算接口,产生一些数据运行日志。在这个过程中,会多次访问系统,触发拼团接口的限流操作。多一些日志也能更好的让 Ai MCP 进行分析。
# 4. 查看日志
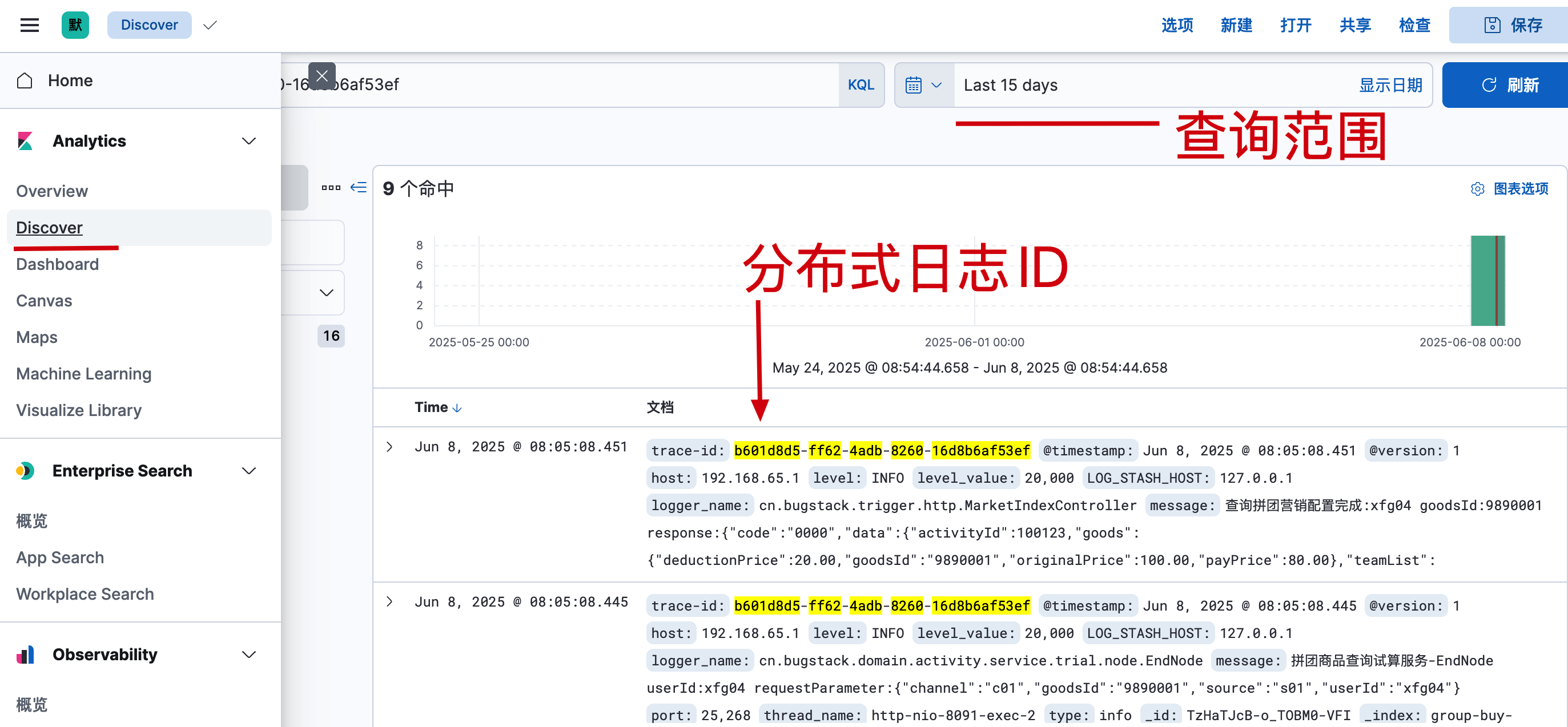
- 配置文章后,访问 Kibana 数据可视化后台,这会你可以看到上报上来的日志信息。
- 到这里,日志配置完成。接下来,我们就可以就 Ai MCP,来访问日志了。
# 三、日志分析
AI MCP 是小傅哥社群内的另外一套项目,《DeepSeek RAG、MCP、Agent》 (opens new window) 智能体,课程。课程里有讲解如何开发和使用 MCP 服务,以及构建 Agent 智能体。地址:https://t.zsxq.com/GwNZp (opens new window) - 感兴趣的伙伴可以进入学习
这里小傅哥选择一个 ElasticSearch MCP 服务,对接到咱们的 ELK 日志上,通过对接的 MCP 服务帮我们检索日志。
# 1. 环境说明
- AI 对话客户端;https://claude.ai/download - 不非得使用这个客户端。像是 trae.ai、cursor 等,能配置 mcp 服务的都可以的。
- 发码平台:https://sms-activate.io/ -
claude.ai 注册需要使用 - node 环境,需要 v18+ https://nodejs.org/en/download
- mcp 服务01;https://github.com/modelcontextprotocol/servers/tree/main/src/filesystem
- mcp 服务02;https://github.com/elastic/mcp-server-elasticsearch
# 2. 客户端使用
# 2.1 配置文件
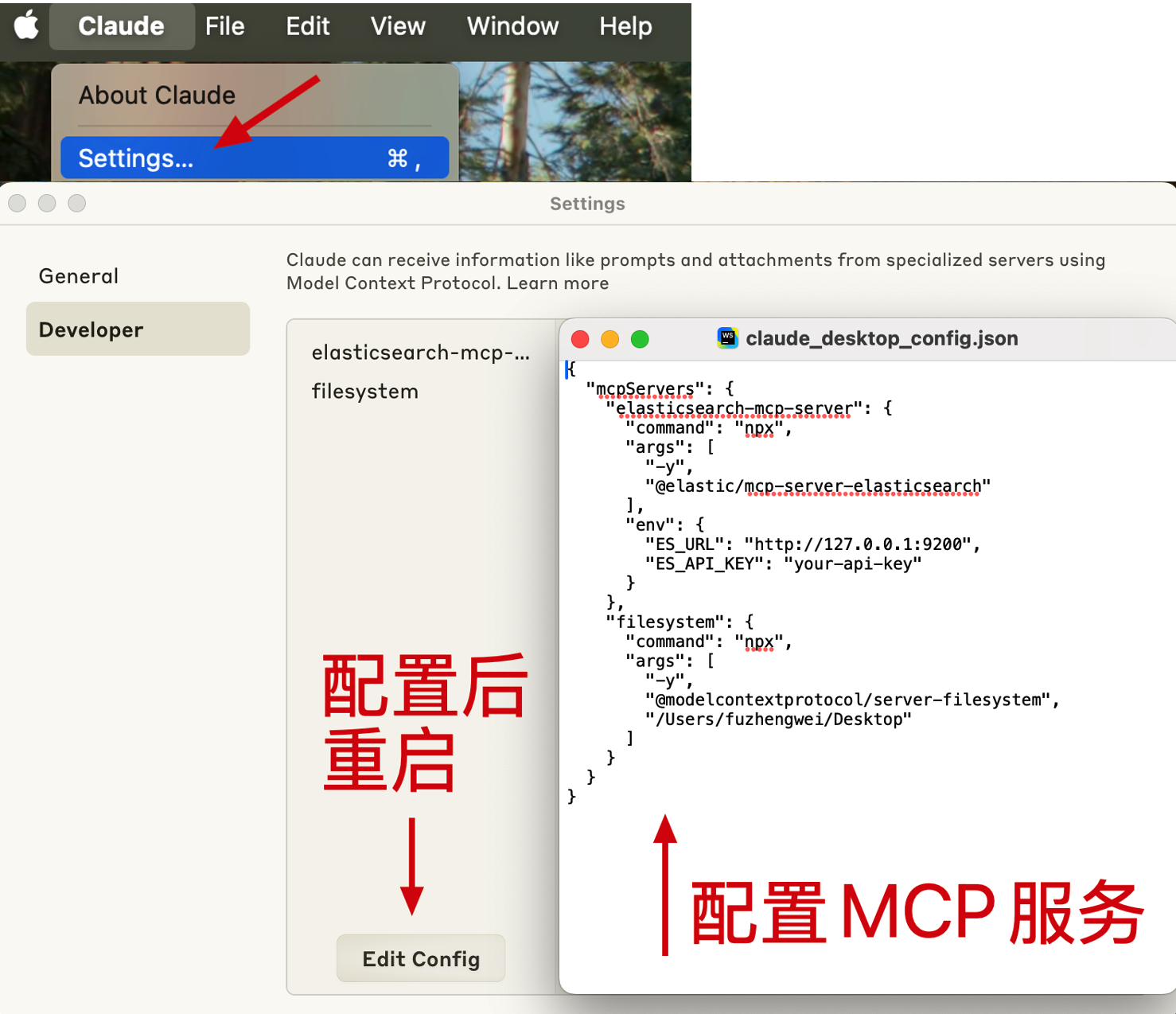
{
"mcpServers": {
"elasticsearch-mcp-server": {
"command": "npx",
"args": [
"-y",
"@elastic/mcp-server-elasticsearch"
],
"env": {
"ES_URL": "http://127.0.0.1:9200",
"ES_API_KEY": "your-api-key"
}
},
"filesystem": {
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-filesystem",
"/Users/fuzhengwei/Desktop"
]
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
- 配置后要重启客户端。注意
/Users/fuzhengwei/Desktop更换为你的文件夹。
# 2.2 对话提问
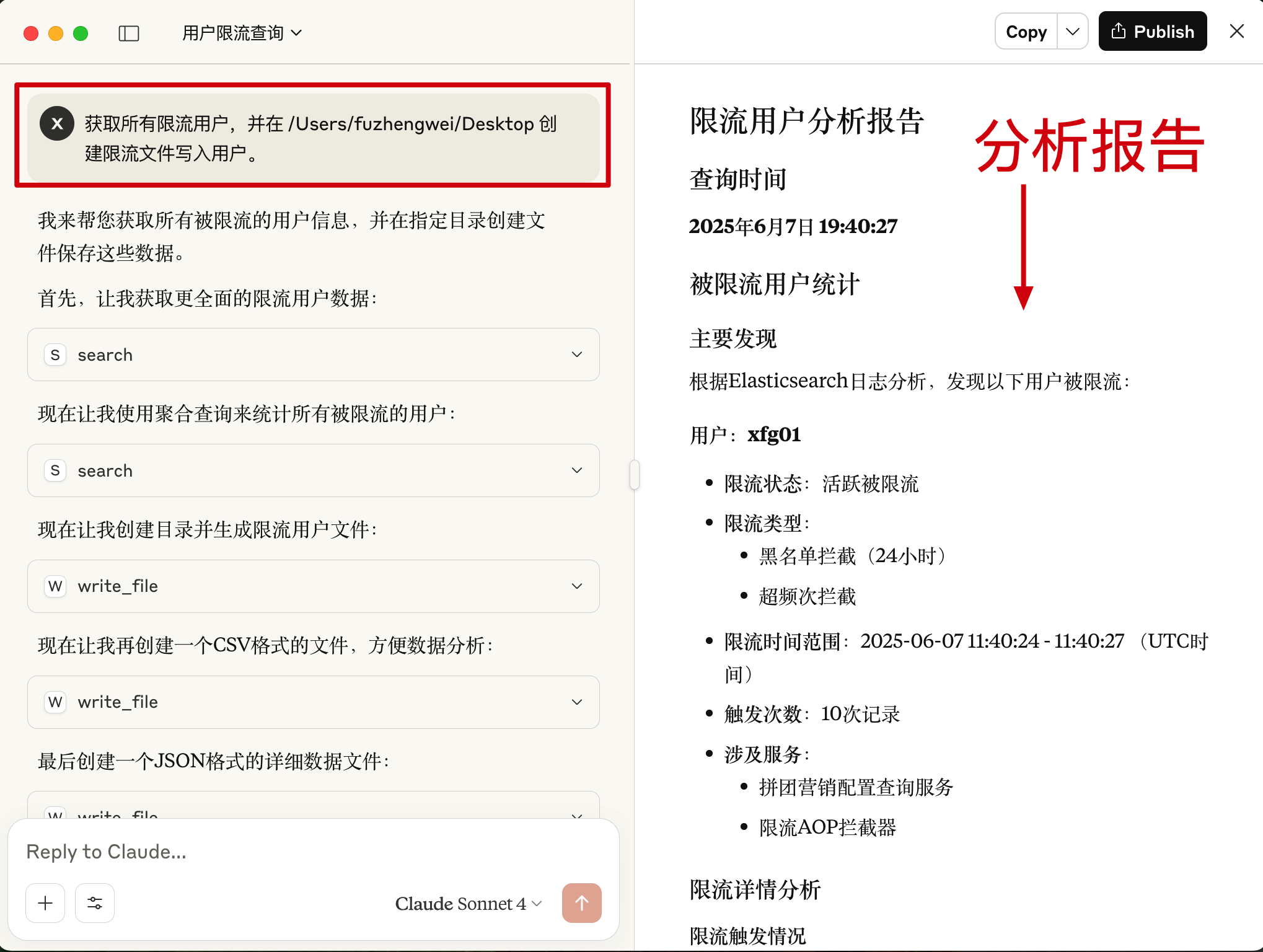
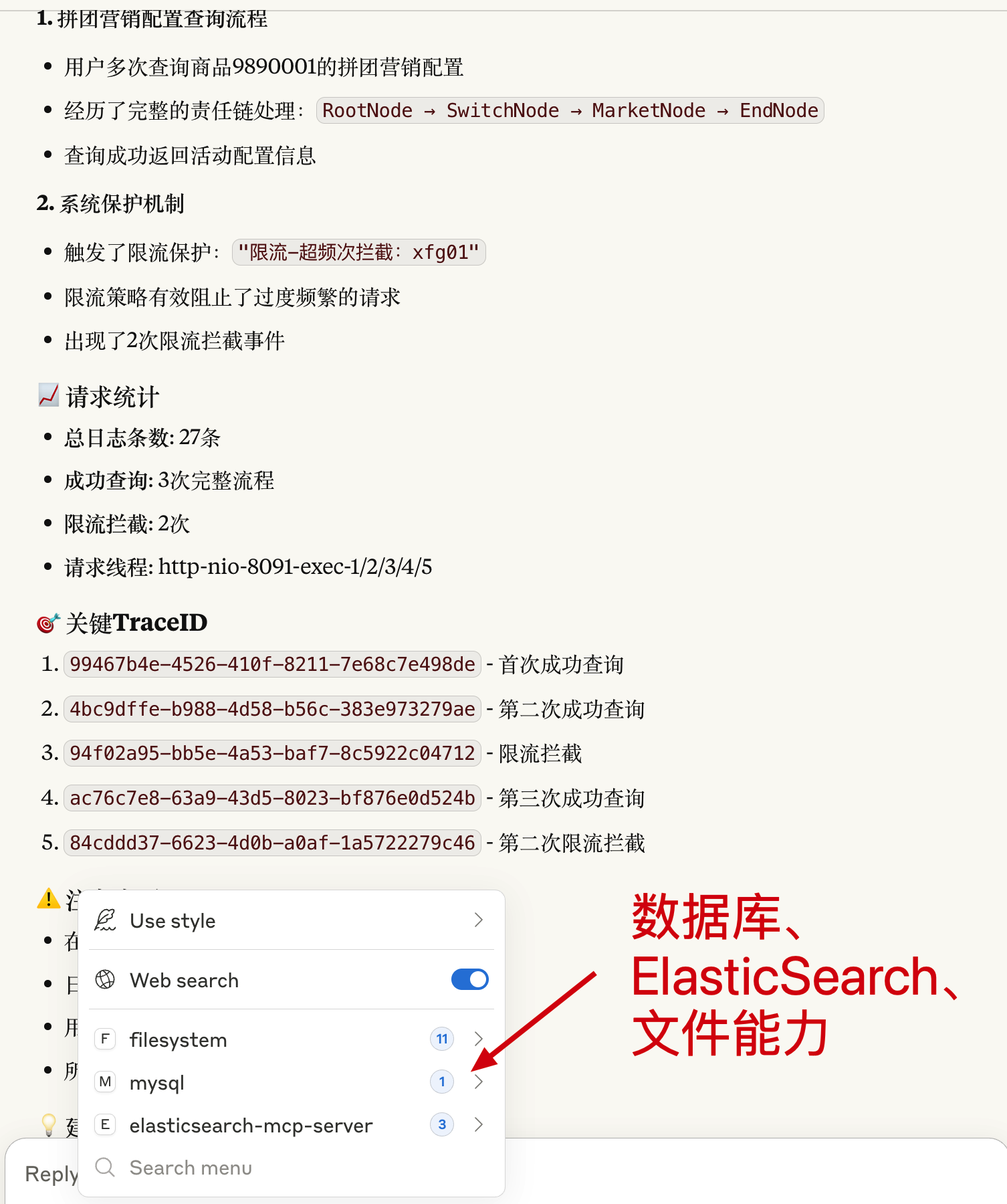
- 对话提问:
获取所有限流用户,并在 /Users/fuzhengwei/Desktop 创建限流文件写入用户。 - 这样他就可以通过 ES 查询我们产生的日志数据,并给出分析报告。
# 2.3 日志文件
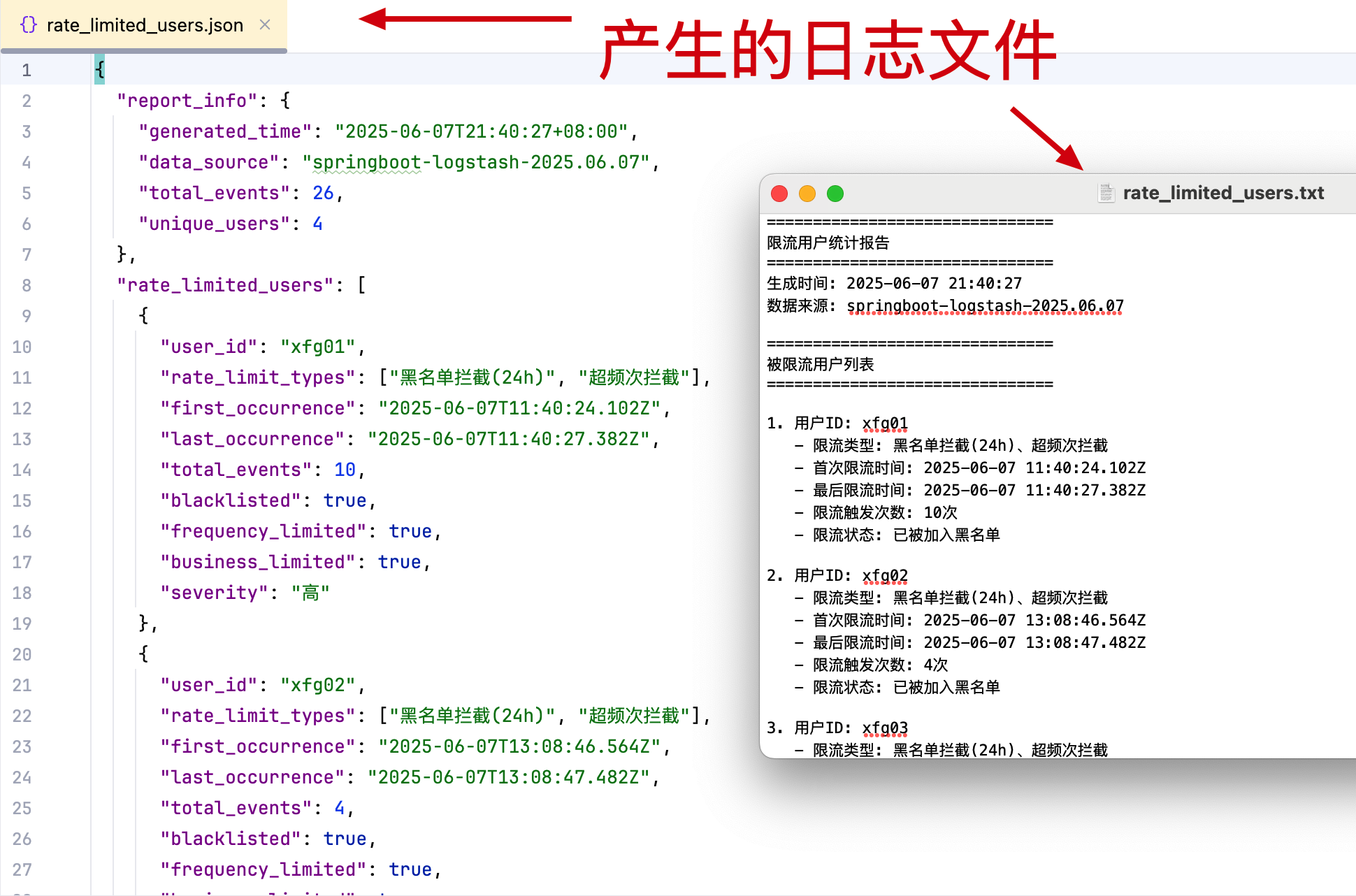
- 打开产生的日志文件,可以把限流的用户拉取出来。方便我们分析提供问题。
# 3. 代码调用
这部分涉及到星球的 AI Agent 项目,工程地址:https://gitcode.net/KnowledgePlanet/ai-agent-station-study (opens new window)
# 3.1 直接调用
package cn.bugstack.ai.test.spring.ai;
@Slf4j
@RunWith(SpringRunner.class)
@SpringBootTest
public class AiAgentMCPESTest {
private ChatModel chatModel;
private ChatClient chatClient;
@Resource
private PgVectorStore vectorStore;
public static final String CHAT_MEMORY_CONVERSATION_ID_KEY = "chat_memory_conversation_id";
public static final String CHAT_MEMORY_RETRIEVE_SIZE_KEY = "chat_memory_response_size";
@Before
public void init() {
OpenAiApi openAiApi = OpenAiApi.builder()
.baseUrl("https://apis.itedus.cn")
.apiKey("sk-vo81adWzUz1G0LBQ1cF1B804A1E04aC*****可申请")
.completionsPath("v1/chat/completions")
.embeddingsPath("v1/embeddings")
.build();
chatModel = OpenAiChatModel.builder()
.openAiApi(openAiApi)
.defaultOptions(OpenAiChatOptions.builder()
.model("gpt-4.1-mini")
.toolCallbacks(new SyncMcpToolCallbackProvider(stdioMcpClientElasticsearch()).getToolCallbacks())
.build())
.build();
}
@Test
public void test_chat_model_call() {
Prompt prompt = Prompt.builder()
.messages(new UserMessage(
"""
有哪些工具可以使用
"""))
.build();
ChatResponse chatResponse = chatModel.call(prompt);
log.info("测试结果(call):{}", JSON.toJSONString(chatResponse));
}
@Test
public void test_chat_model_call_es() {
Prompt prompt = Prompt.builder()
.messages(new UserMessage(
"""
查询xfg01日志,DSL 语句;
{
`index`: `springboot-logstash-2025.06.07`,
`queryBody`: {
`size`: 10,
`sort`: [
{
`@timestamp`: {
`order`: `desc`
}
}
],
`query`: {
`match`: {
`message`: `xfg01`
}
}
}
}
"""))
.build();
ChatResponse chatResponse = chatModel.call(prompt);
log.info("测试结果(call):{}", JSON.toJSONString(chatResponse));
}
/**
* https://sai.baidu.com/server/Elasticsearch%2520MCP%2520Server/awesimon?id=02d6b7e9091355b91fed045b9c80dede
* https://github.com/elastic/mcp-server-elasticsearch
*/
public McpSyncClient stdioMcpClientElasticsearch() {
Map<String, String> env = new HashMap<>();
env.put("ES_URL","http://127.0.0.1:9200");
env.put("ES_API_KEY","none");
var stdioParams = ServerParameters.builder("npx")
.args("-y", "@elastic/mcp-server-elasticsearch")
.env(env)
.build();
var mcpClient = McpClient.sync(new StdioClientTransport(stdioParams))
.requestTimeout(Duration.ofSeconds(100)).build();
var init = mcpClient.initialize();
System.out.println("Stdio MCP Initialized: " + init);
return mcpClient;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109

- 以上代码,就是对接的 mcp 服务,以及通过
查询xfg01日志,DSL 语句;来操作 ES。
# 3.2 动态调用(Agent)
private String buildSystemPrompt() {
return """
你是一个专业的日志分析助手,具备以下能力:
1. 可以查询Elasticsearch索引列表 - 使用list_indices()函数
2. 可以获取索引字段映射 - 使用get_mappings(index)函数
3. 可以执行Elasticsearch搜索 - 使用search(index, queryBody)函数
当用户询问限流相关问题时,请按以下步骤执行:
**步骤1:探索数据源**
- 首先调用list_indices()查看所有可用的索引
- 识别可能包含日志信息的索引(通常包含log、logstash等关键词)
**步骤2:分析数据结构**
- 对目标索引调用get_mappings()查看字段结构
- 重点关注message、level、timestamp等字段
**步骤3:构建搜索查询**
- 使用多种限流相关关键词搜索:限流、rate limit、throttle、blocked、超过限制、黑名单、超频次
- 按时间倒序排列结果
- 示例查询结构:
{
`index`: `group-buy-market-log-2025.06.08`,
`queryBody`: {
`size`: 10,
`sort`: [
{
`@timestamp`: {
`order`: `desc`
}
}
],
`query`: {
`match`: {
`message`: `xfg01`
}
}
}
}
**步骤4:优化搜索策略**
- 如果初始搜索结果不理想,尝试使用wildcard查询
- 如果需要,使用单一关键词进行精确匹配
**步骤5:分析结果**
- 从搜索结果中提取用户信息
- 识别限流类型(黑名单、超频次等)
- 统计触发次数和时间分布
- 分析影响的服务和功能
**输出格式要求:**
- 明确列出被限流的用户ID
- 说明限流类型和原因
- 提供触发时间和频率信息
- 给出分析建议
现在开始执行查询任务。
""";
}
@Test
public void queryRateLimitedUsers() {
// 第一步:系统初始化提示词
String systemPrompt = buildSystemPrompt();
// 第二步:用户查询提示词
String userQuery = "查询哪个用户被限流了";
// 第三步:构建完整的提示词
String fullPrompt = buildFullPrompt(systemPrompt, userQuery);
// 第四步:调用AI模型
Prompt prompt = Prompt.builder()
.messages(new UserMessage(fullPrompt))
.build();
ChatResponse chatResponse = chatModel.call(prompt);
log.info("测试结果:{}", chatResponse.getResult().getOutput().getText());
}
public String queryRateLimitedUsersStepByStep() {
StringBuilder result = new StringBuilder();
// 步骤1:查询索引列表
String step1Prompt = buildStepPrompt("步骤1:查询所有可用的Elasticsearch索引",
"请调用list_indices()函数查看所有可用的索引,并识别可能包含日志的索引。");
result.append(executeStep(step1Prompt)).append("\n\n");
// 步骤2:获取索引映射
String step2Prompt = buildStepPrompt("步骤2:获取日志索引的字段映射",
"请对识别出的日志索引调用get_mappings()函数,查看字段结构,重点关注message、level、timestamp等字段。");
result.append(executeStep(step2Prompt)).append("\n\n");
// 步骤3:搜索限流日志
String step3Prompt = buildStepPrompt("步骤3:搜索限流相关日志",
"请使用多种限流相关关键词(限流、rate limit、throttle、blocked、超过限制等)搜索日志,按时间倒序排列。");
result.append(executeStep(step3Prompt)).append("\n\n");
// 步骤4:分析结果
String step4Prompt = buildStepPrompt("步骤4:分析限流用户",
"请分析搜索结果,提取被限流的用户信息,包括用户ID、限流类型、触发次数等,并生成详细报告。");
result.append(executeStep(step4Prompt)).append("\n\n");
return result.toString();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
================================================================================
📝 执行步骤日志:
================================================================================
步骤 1: 经过索引查询,我们确定了一个名为 `group-buy-market-log-2025.06.08` 的索引,该索引包含了日志记录。在分析索引字段映射之后,发现字段 `message` 是存储日志内容的主要字段。因此,我们构建了一个搜索查询来查找日志中与“限流”相关的记录。
在向 Elasticsearch 发送查询请求时,首次尝试做了一个布尔查询,但由于格式问题请求失败。随后,我使用了一个更简洁的 `query_string` 查询,该查询成功返回了 16 条相关记录。这些记录主要显示了不同用户超限流量被拦截的情况。 具体限制用户如下:
- 用户标识: `xfg01`
- 用户标识: `liergou`
- 用户标识: `xiaofuge`
- 用户标识: `zhangsan`
- 用户标识: `xiefeiji`
这些记录均包含了时间戳和其他上下文信息,如日志级别、线程名和来源等。
2
3
4
5
6
7
8
9
10
11
12
13
14
- 基于提示词和代码逻辑,可以动态执行调用和结果分析。Ai 提示词是构建 Agent 非常重要的一项技术,因为 提示词 = Ai 大脑!
# 四、扩展能力
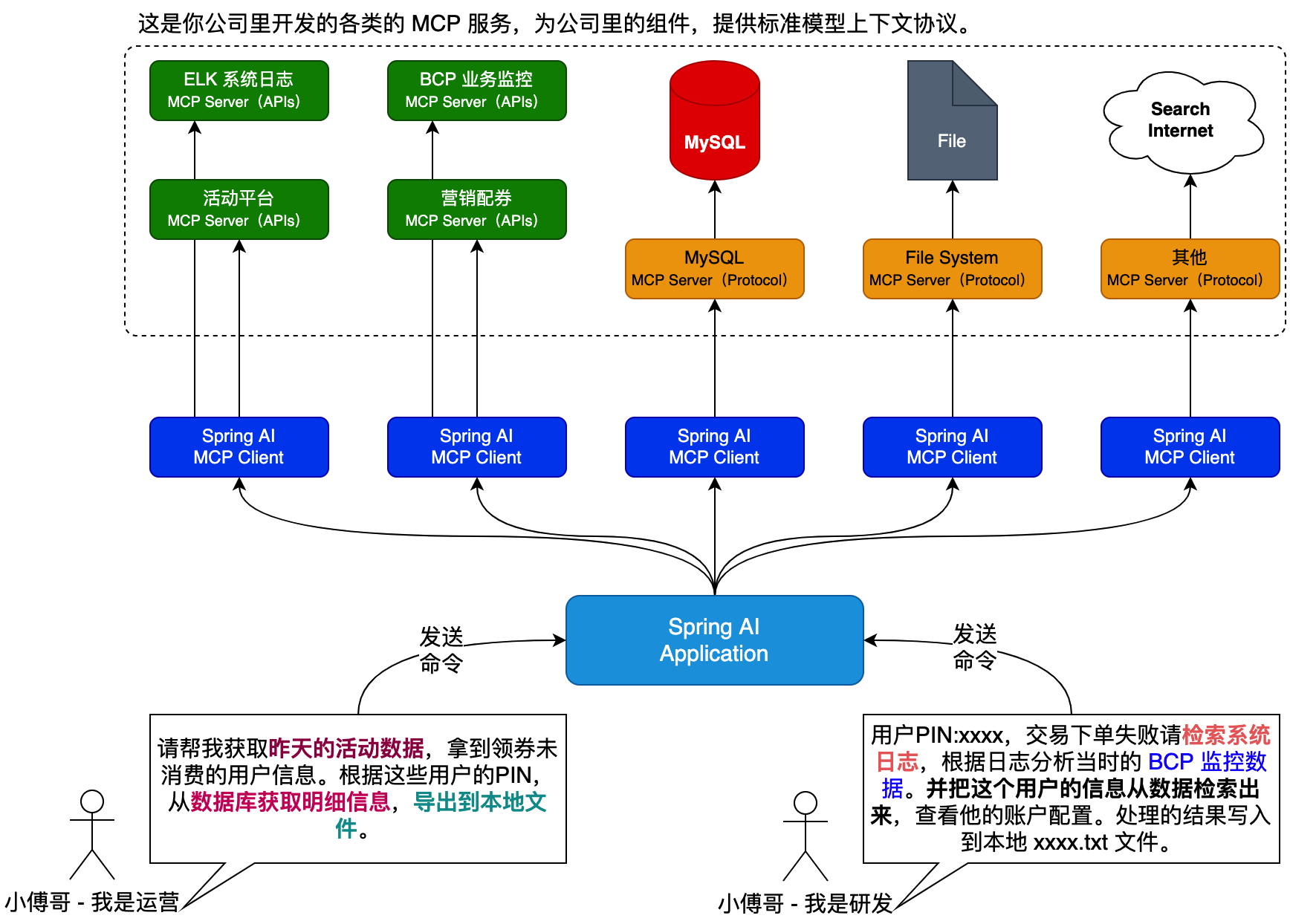
- Ai MCP 服务,也就是 Agent 能力,还可以用于全面的系统运行分析,帮助我们快速的处理线上运行情况。
好啦,这次我们先分享关于 Ai MCP 如何为日志检索提效。下次我们在分析关于监控处理。

京公网安备 11030102010881号
| GPL Licensed | Copyright © 2019 小傅哥,All rights reserved.