# 【小场景训练营】敏感词内容审核 —— 如果你的论坛被人乱留言怎么办?
作者:小傅哥
博客:https://bugstack.cn (opens new window)
沉淀、分享、成长,让自己和他人都能有所收获!😄
哈喽,大家好我是技术UP主小傅哥。
常听到一句话:”你很难赚到你认知以外的钱💰“,屁!不是很难,是压根赚不到。你以为要是你做也能做,但其实除了你能看见的以外,还有很多东西都不知道。

我看过不少小伙伴自己上线过带有评论功能的博客,或是能进行通信的聊天室。但最后都没运营多久就关停了,除了能花钱解决的服务器成本,还有是自身的研发的系统流程不够健全。其中非常重要的一点是舆情敏感内容的审核,如果你做这类应用的处理,一定要对接上相应的内容安全审核。
那么,接下来小傅哥就给大家分享下,如何对接内容安全审核,并在 DDD 分层结构下实现一个对应的规则过滤服务。
文末提供了「星球:码农会锁」🧧优惠加入方式,以及本节课程的代码地址。项目演示地址:https://gaga.plus (opens new window)
# 一、场景说明
在本节小傅哥会通过 DDD 分层架构设计,开发出一个敏感词、内容安全审核过滤操作的规则处理器。在这个过程大家可以学习到 DDD 分层调用流程、规则模型的搭建、敏感词和内容审核的使用。
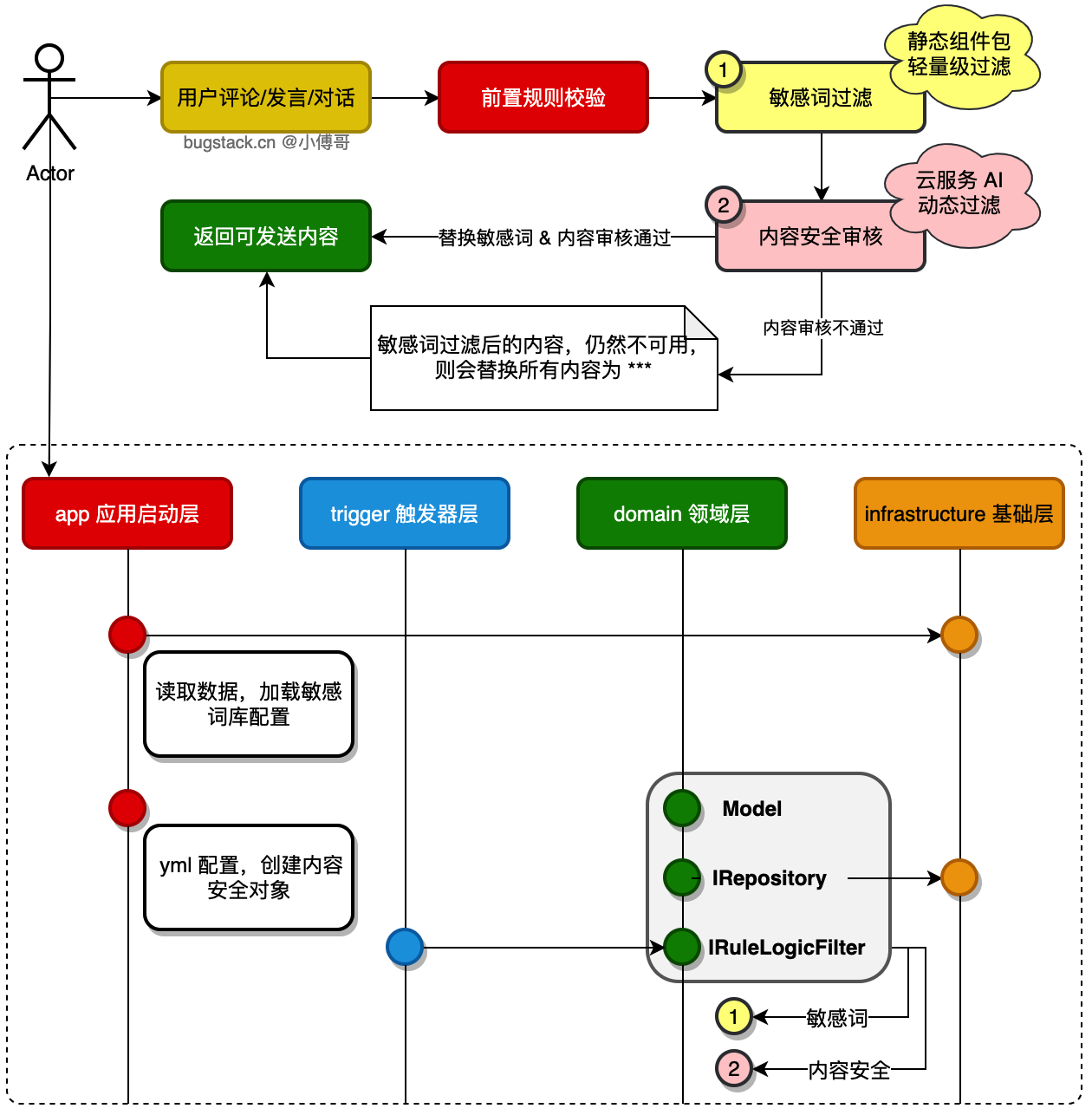
如图,上半部分是业务流程,下半部分是 DDD 分层结构中的实现。
- 业务流程上,以用户发送的提交给服务端的内容进行审核过滤,优先使用敏感词进行替换单词组。过滤后过内容审核,一般各个云平台都有提供内容审核的接口,如;京东云、百度云、腾讯云都有提供。一般价格在
0.0015 元/条 - 系统实现上,以 DDD 分层架构实现一个内容审核的流程。app 配置组件和启动应用、trigger 提供 http 调用、domain 编写核心逻辑和流程、infrastructure 提供 dao 的基础操作。
# 二、内容审核 - SDK 使用
一般舆情内容审核分为两种,一种是静态配置数据的 SDK 组件,也叫敏感词过滤。另外一种是实时动态的由各个第三方提供的内容审核接口服务。这类的就是前面提到的,在各个云平台都有提供。
这里小傅哥先带着大家做下最基本的调用案例,之后再基于 DDD 工程实现整个代码开发。
# 1. 敏感词
地址:https://github.com/houbb/sensitive-word (opens new window) - 开源的敏感词库组件
<dependency>
<groupId>com.github.houbb</groupId>
<artifactId>sensitive-word</artifactId>
<version>0.8.0</version>
</dependency>
2
3
4
5
案例代码
@Test
public void test_sensitive_word() {
boolean contains = sensitiveWordBs.contains("小傅哥喜欢烧烤臭毛蛋,豆包爱吃粑粑,如果想吃订购请打电话:13900901878");
log.info("是否被敏感词拦截:{}", contains);
}
@Test
public void test_sensitive_word_findAll() {
List<String> list = sensitiveWordBs.findAll("小傅哥喜欢烧烤臭毛蛋,豆包爱吃粑粑,如果想吃订购请打电话:13900901878");
log.info("测试结果:{}", JSON.toJSONString(list));
}
@Test
public void test_sensitive_word_replace() {
String replace = sensitiveWordBs.replace("小傅哥喜欢烧烤臭毛蛋,豆包爱吃粑粑,如果想吃订购请打电话:13900901878");
log.info("测试结果:{}", replace);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
- 敏感词组件提供了大量的风险词过滤,同时可以基于组件的文档完成自定义敏感词的增改删减操作。
本文在工程中已提供 - 敏感词组件提供了判断、查找、过滤操作。还有你可以把检测到的敏感词替换为
*或者空格。
# 2. 内容审核
- 京东云:https://www.jdcloud.com/cn/products/censor (opens new window)
- 百度云:https://ai.baidu.com/censoring#/strategylist (opens new window)
- 腾讯云:https://cloud.tencent.com/product/tms (opens new window)
这里小傅哥以其中的一个百度云为例,为大家展示内容安全审核的使用。
<!-- 百度内容审核 https://mvnrepository.com/artifact/com.baidu.aip/java-sdk -->
<dependency>
<groupId>com.baidu.aip</groupId>
<artifactId>java-sdk</artifactId>
<version>4.16.17</version>
</dependency>
2
3
4
5
6
# 2.1 配置应用
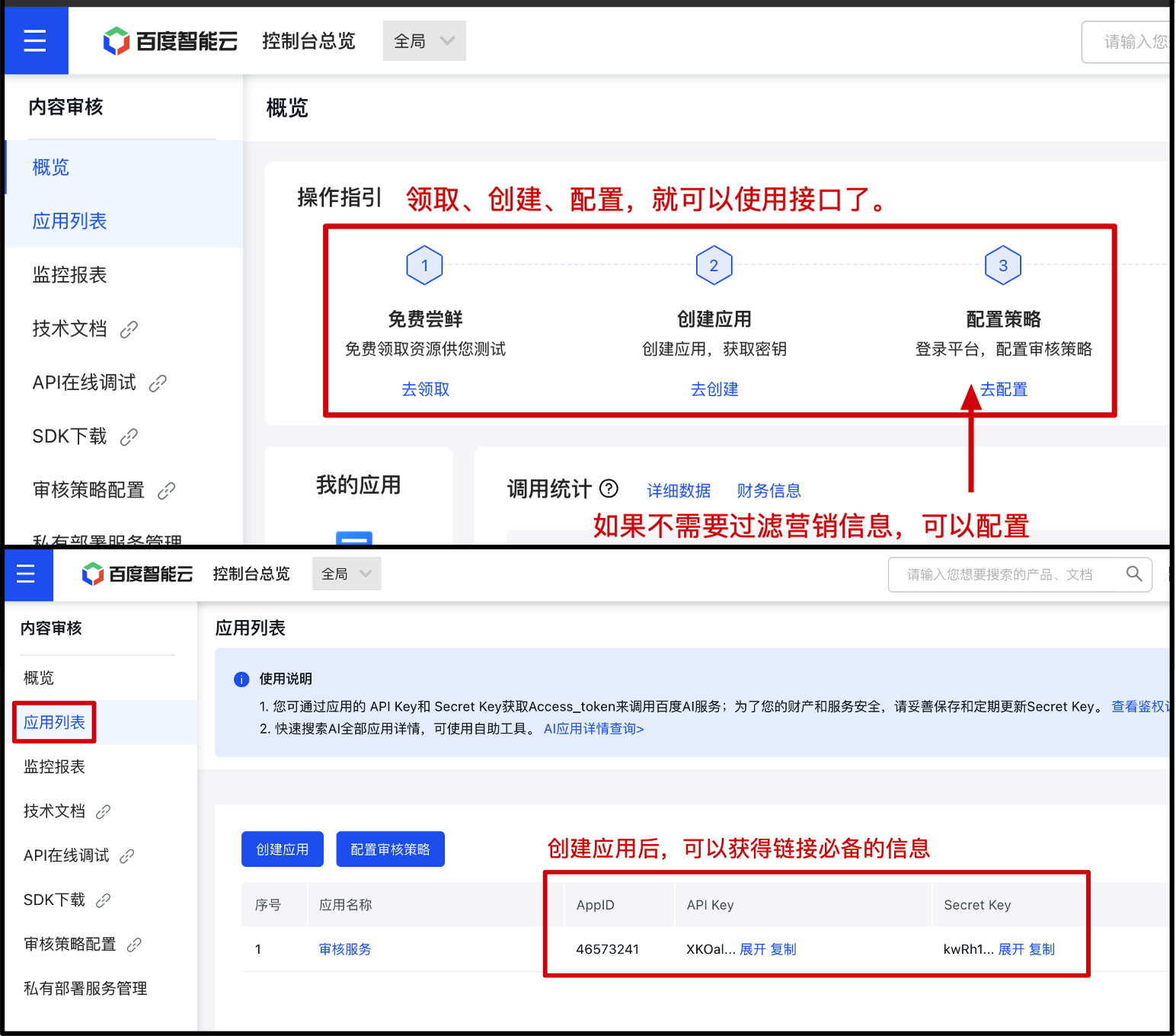
- 先领取免费的调用次数,之后创建应用。创建应用后就可以获得连接信息;appid、apikey、secretkey
- 另外是策略配置,如果你在过滤中不需要检测用户发的应用营销信息,那么是可以不检测的。
# 2.2 测试服务
//设置APPID/AK/SK
public static final String APP_ID = "{APP_ID}";
public static final String API_KEY = "{API_KEY}";
public static final String SECRET_KEY = "{SECRET_KEY}";
private AipContentCensor client;
@Before
public void init() {
client = new AipContentCensor(APP_ID, API_KEY, SECRET_KEY);
// 可选:设置网络连接参数
client.setConnectionTimeoutInMillis(2000);
client.setSocketTimeoutInMillis(60000);
}
@Test
public void test_textCensorUserDefined() throws JSONException {
for (int i = 0; i < 1; i++) {
JSONObject jsonObject = client.textCensorUserDefined("小傅哥喜欢烧烤臭毛蛋,豆包爱吃粑粑,如果想吃订购请打电话:13900901878");
if (!jsonObject.isNull("error_code")) {
log.info("测试结果:{}", jsonObject.get("error_code"));
} else {
log.info("测试结果:{}", jsonObject.toString());
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
测试结果
13:41:16.393 [main] INFO com.baidu.aip.client.BaseClient - get access_token success. current state: STATE_AIP_AUTH_OK
13:41:16.396 [main] DEBUG com.baidu.aip.client.BaseClient - current state after check priviledge: STATE_TRUE_AIP_USER
13:41:16.495 [main] INFO cn.bugstack.x.api.test.BaiduAipContentCensorTest - 测试结果:{"conclusion":"合规","log_id":17046060767025067,"isHitMd5":false,"conclusionType":1}
2
3
- 应为过滤掉了营销信息,比如手机号。那么就会返回
合规
# 三、应用实现 - DDD 架构
做了以上的基本调用案例以后,我们来看下在系统中怎么运用这些基础功能完成业务诉求。
# 1. 工程结构
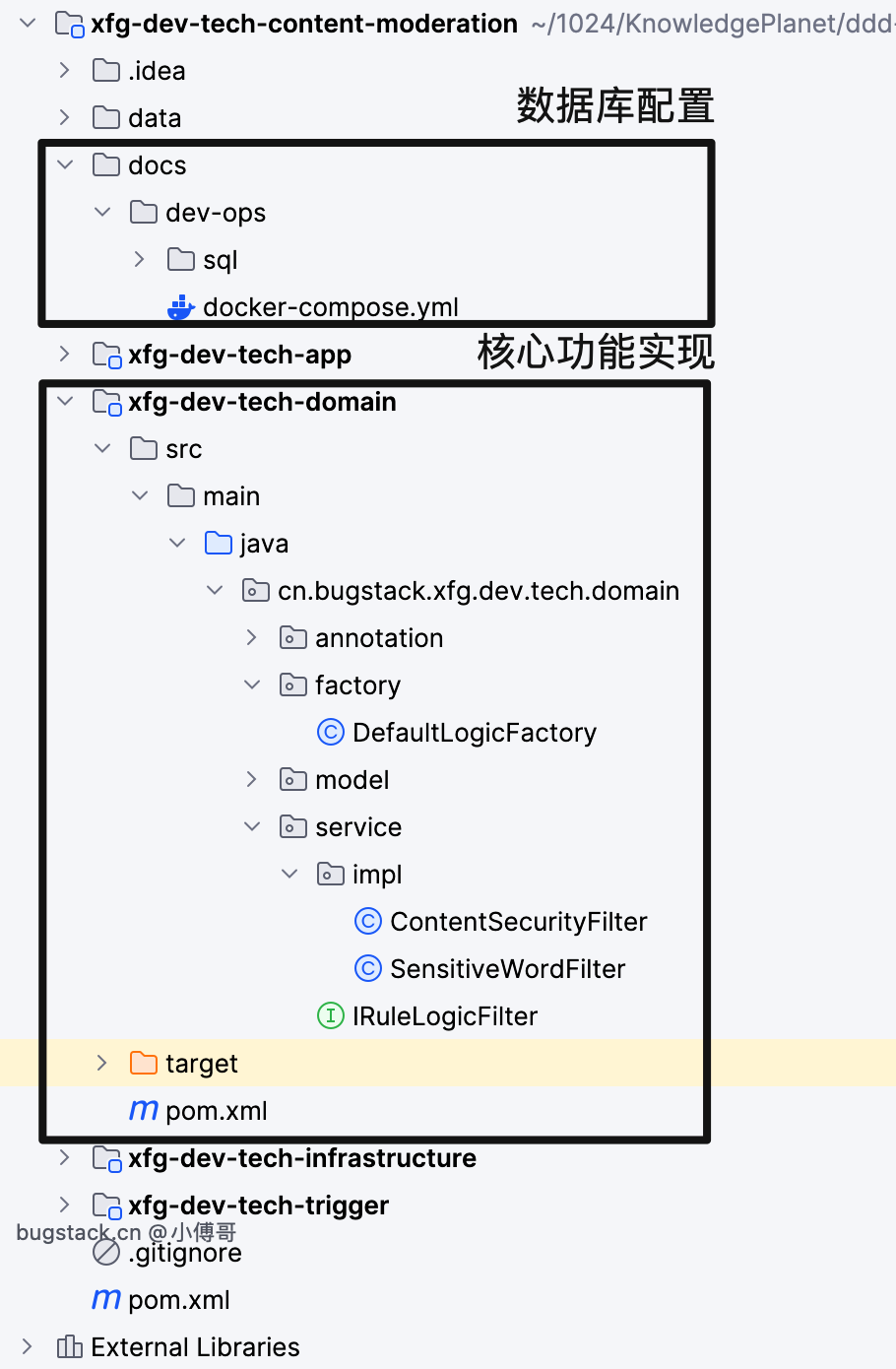
- docs 下提供了 docker 安装 mysql 以及初始化数据库配置的脚本。因为本文的案例,可以满足你在数据库中增加敏感词配置。
- app 是应用的启动层,如上我们所需的敏感词和内容审核,都在app层下配置启动处理。
- domain 领域层通过策略+工厂,实现规则过滤服务。
# 2. 数据库表
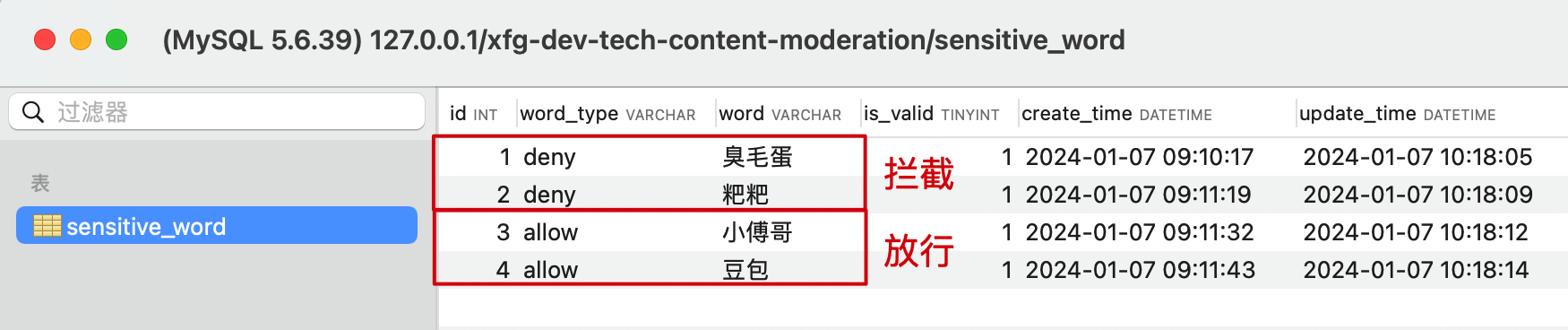
- 在docs 提供了数据库初始化的脚本语句,你可以导入到自己的数据库,或者使用 docker 脚本安装测试。—— 注意已经安装过 mysql 占用了 3306 端口的话,记得修改 docker 脚本安装 mysql 的端口。
- 配置到数据库中的敏感词方便管理和使用,为了性能考虑也可以考虑使用 redis 做一层缓存。
# 3. 配置加载
# 3.1 敏感词初始化
@Configuration
public class SensitiveWordConfig {
@Bean
public SensitiveWordBs sensitiveWordBs(IWordDeny wordDeny, IWordAllow wordAllow) {
return SensitiveWordBs.newInstance()
.wordDeny(wordDeny)
.wordAllow(wordAllow)
.ignoreCase(true)
.ignoreWidth(true)
.ignoreNumStyle(true)
.ignoreChineseStyle(true)
.ignoreEnglishStyle(true)
.ignoreRepeat(false)
.enableNumCheck(true)
.enableEmailCheck(true)
.enableUrlCheck(true)
.enableWordCheck(true)
.numCheckLen(1024)
.init();
}
@Bean
public IWordDeny wordDeny(ISensitiveWordDao sensitiveWordDao) {
return new IWordDeny() {
@Override
public List<String> deny() {
return sensitiveWordDao.queryValidSensitiveWordConfig("deny");
}
};
}
@Bean
public IWordAllow wordAllow(ISensitiveWordDao sensitiveWordDao) {
return new IWordAllow() {
@Override
public List<String> allow() {
return sensitiveWordDao.queryValidSensitiveWordConfig("allow");
}
};
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
- wordDeny、wordAllow 是两个自定义的拦截和放行的敏感词列表,这里小傅哥设计从数据库中查询。可以方便动态的维护。
# 3.2 内容安全初始化
# 内容安全
baidu:
aip:
app_id: 46573000
api_key: XKOalQOgDBUrvgLBplvu****
secret_key: kwRh1bEhETYWpq9thzyySdFDPKUk****
2
3
4
5
6
- 自定义一个配置文件类 AipContentCensorConfigProperties
@Bean
public AipContentCensor aipContentCensor(AipContentCensorConfigProperties properties) {
AipContentCensor client = new AipContentCensor(properties.getApp_id(), properties.getApi_key(), properties.getSecret_key());
client.setConnectionTimeoutInMillis(2000);
client.setSocketTimeoutInMillis(60000);
return client;
}
2
3
4
5
6
7
- 这里我们来统一创建 AipContentCensor 对象,用于有需要使用的地方处理内容审核。
# 4. 规则实现
源码: cn.bugstack.xfg.dev.tech.domain.service.IRuleLogicFilter
public interface IRuleLogicFilter {
RuleActionEntity<RuleMatterEntity> filter(RuleMatterEntity ruleMatterEntity);
}
2
3
4
5
- 定义一个统一的规则过滤接口
# 4.1 敏感词
@Slf4j
@Component
@LogicStrategy(logicMode = DefaultLogicFactory.LogicModel.SENSITIVE_WORD)
public class SensitiveWordFilter implements IRuleLogicFilter {
@Resource
private SensitiveWordBs words;
@Override
public RuleActionEntity<RuleMatterEntity> filter(RuleMatterEntity ruleMatterEntity) {
// 敏感词过滤
String content = ruleMatterEntity.getContent();
String replace = words.replace(content);
// 返回结果
return RuleActionEntity.<RuleMatterEntity>builder()
.type(LogicCheckTypeVO.SUCCESS)
.data(RuleMatterEntity.builder().content(replace).build())
.build();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 4.2 安全内容
@Slf4j
@Component
@LogicStrategy(logicMode = DefaultLogicFactory.LogicModel.CONTENT_SECURITY)
public class ContentSecurityFilter implements IRuleLogicFilter {
@Resource
private AipContentCensor aipContentCensor;
@Override
public RuleActionEntity<RuleMatterEntity> filter(RuleMatterEntity ruleMatterEntity) {
JSONObject jsonObject = aipContentCensor.textCensorUserDefined(ruleMatterEntity.getContent());
if (!jsonObject.isNull("conclusion") && "不合规".equals(jsonObject.get("conclusion"))) {
return RuleActionEntity.<RuleMatterEntity>builder()
.type(LogicCheckTypeVO.REFUSE)
.data(RuleMatterEntity.builder().content("内容不合规").build())
.build();
}
// 返回结果
return RuleActionEntity.<RuleMatterEntity>builder()
.type(LogicCheckTypeVO.SUCCESS)
.data(ruleMatterEntity)
.build();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 5. 工厂使用
public class DefaultLogicFactory {
public Map<String, IRuleLogicFilter> logicFilterMap = new ConcurrentHashMap<>();
public DefaultLogicFactory(List<IRuleLogicFilter> logicFilters) {
logicFilters.forEach(logic -> {
LogicStrategy strategy = AnnotationUtils.findAnnotation(logic.getClass(), LogicStrategy.class);
if (null != strategy) {
logicFilterMap.put(strategy.logicMode().getCode(), logic);
}
});
}
public RuleActionEntity<RuleMatterEntity> doCheckLogic(RuleMatterEntity ruleMatterEntity, LogicModel... logics) {
RuleActionEntity<RuleMatterEntity> entity = null;
for (LogicModel model : logics) {
entity = logicFilterMap.get(model.code).filter(ruleMatterEntity);
if (!LogicCheckTypeVO.SUCCESS.equals(entity.getType())) return entity;
ruleMatterEntity = entity.getData();
}
return entity != null ? entity :
RuleActionEntity.<RuleMatterEntity>builder()
.type(LogicCheckTypeVO.SUCCESS)
.data(ruleMatterEntity)
.build();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
- 定义出规则的使用工厂,通过构造函数的方式注入已经实现了接口 IRuleLogicFilter 的 N 个规则,注入到 Map 中
Map<String, IRuleLogicFilter> logicFilterMap - doCheckLogic 根据入参来过滤需要处理的规则。这里可以看到每过滤一个规则都会把参数继续传递给下一个规则继续筛选。
有点像层层过筛子的感觉
# 四、测试验证
- 测试前确保已经初始化了库表
docs/dev-ops/sql/xfg-dev-tech-content-moderation.sql application-dev.yml配置百度内容安全参数和数据库连接参数。
# 1. 功能测试
@Slf4j
@RunWith(SpringRunner.class)
@SpringBootTest
public class RuleLogicTest {
@Resource
private DefaultLogicFactory defaultLogicFactory;
@Test
public void test() {
RuleActionEntity<RuleMatterEntity> entity = defaultLogicFactory.doCheckLogic(
RuleMatterEntity.builder().content("小傅哥喜欢烧烤臭毛蛋,豆包爱吃粑粑,如果想吃订购请打电话:13900901878").build(),
DefaultLogicFactory.LogicModel.SENSITIVE_WORD,
DefaultLogicFactory.LogicModel.CONTENT_SECURITY
);
log.info("测试结果:{}", JSON.toJSONString(entity));
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
测试结果
24-01-07.14:17:16.988 [main ] INFO BaseClient - get access_token success. current state: STATE_AIP_AUTH_OK
24-01-07.14:17:17.328 [main ] INFO RuleLogicTest - 测试结果:{"data":{"content":"小傅哥喜欢烧烤***,豆包爱吃**,如果想吃订购请打电话:13900901878"},"type":"SUCCESS"}
2
# 2. 接口测试
@RequestMapping(value = "sensitive/rule", method = RequestMethod.GET)
public String rule(String content) {
try {
log.info("内容审核开始 content: {}", content);
RuleActionEntity<RuleMatterEntity> entity = defaultLogicFactory.doCheckLogic(RuleMatterEntity.builder().content(content).build(),
DefaultLogicFactory.LogicModel.SENSITIVE_WORD,
DefaultLogicFactory.LogicModel.CONTENT_SECURITY
);
log.info("内容审核完成 content: {}", entity.getData());
return JSON.toJSONString(entity);
} catch (Exception e) {
log.error("内容审核异常 content: {}", content, e);
return "Err!";
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
接口:http://localhost:8091/api/v1/content/sensitive/rule?content=小傅哥喜欢烧烤臭毛蛋,豆包爱吃粑粑,如果想吃订购请打电话:13900901878

- 那么现在就可以对内容进行审核过滤了。
# 六、加入学习
注意📢,本项目也只是【星球:码农会锁】众多项目中的1个,其他的项目还包括:大营销平台系统、OpenAI 大模型应用、API网关、Lottery抽奖、IM通信、SpringBoot Starter 组件开发、IDEA Plugin 插件开发等,并还有开源项目学习。
如果大家希望通过做有价值的编程项目,提高自己的编程思维和编码能力,可以加入小傅哥的【星球:码农会锁】。加入后解锁🔓所有往期项目,还可以学习后续新开发的项目。
# 七、推荐阅读

京公网安备 11030102010881号
| GPL Licensed | Copyright © 2019 小傅哥,All rights reserved.